The Power of Three: Using Apache Iceberg, Databricks, and Tabular for Data Engineering


Tabular is a centralized table storage for all of your analytical data that can be utilized anywhere, whereas Apache Iceberg is a high-performance and open table format for analytical workloads.
This article will demonstrate how to quickly get up and running using Iceberg in Databricks. The Databricks community edition and Tabular warehouse are used in this walkthrough.
Pre-requisites
Tabular: A warehouse configured and created on S3. Creation of a fully functional warehouse in Tabular is out of scope of this article. Pls follow this blog post for the reference.
Databricks community edition.
Step 1: Get the required jars
Download the Tabular jar from here.
Make sure to choose the compatible version accordingly to the Spark version of the Databricks cluster.
Download the Iceberg jar from here. Make sure to choose the compatible version accordingly to the Spark version of the Databricks cluster.
Make sure to choose the compatible version accordingly to the Spark version of the Databricks cluster.
Step 2: Add jars to Databricks compute cluster
Goto COMPUTE > YOUR_CLUSTER > LIBRARIES tab
Click on “Install new” button to install the downloaded libraries

Once upload you can verify in the Libraries tab.

Step 3: Configure the Databricks cluster
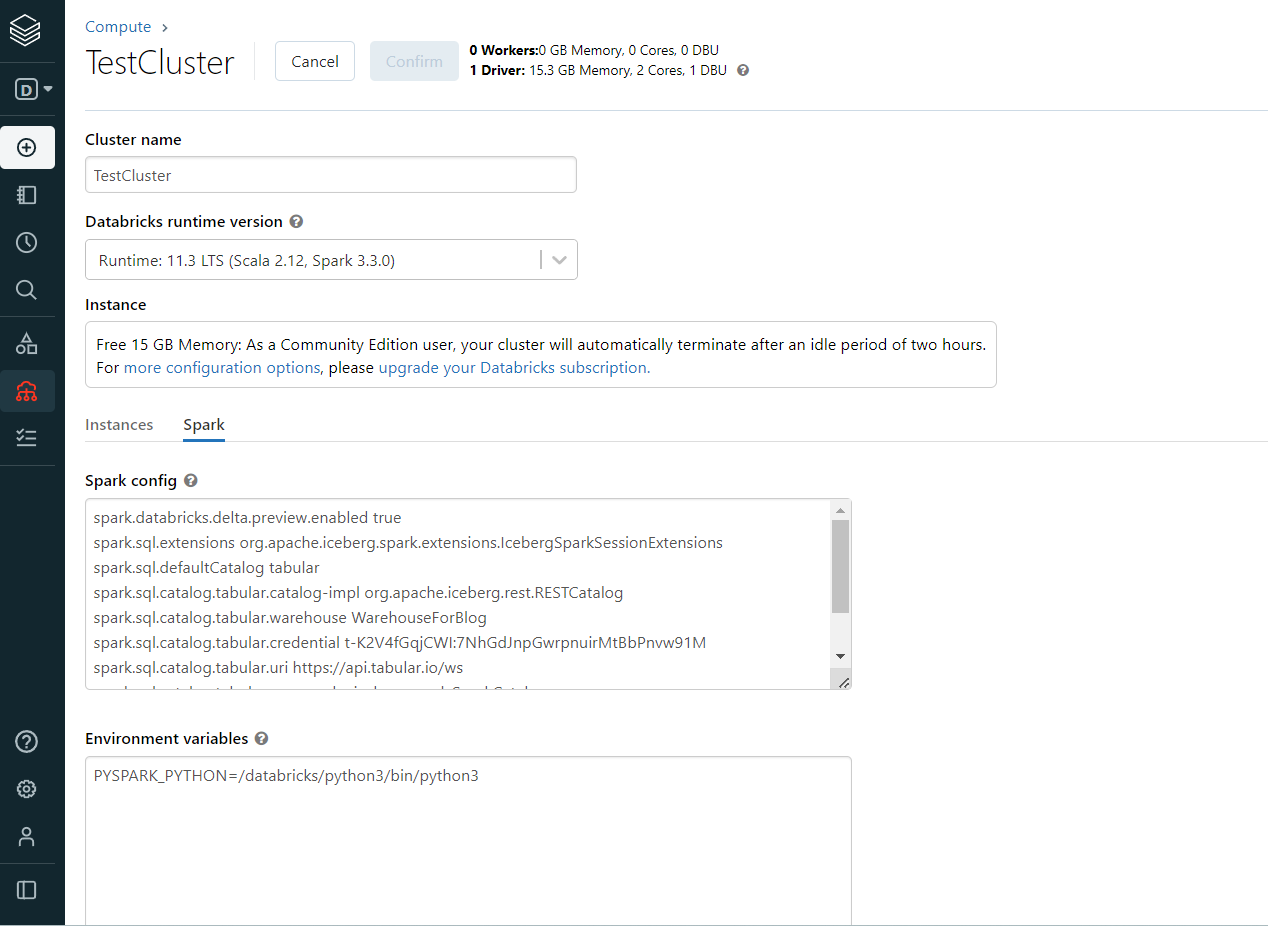
Navigate to CLUSTER > SPARK tab and set the below properties in “Spark config” section -
spark.sql.extensions org.apache.iceberg.spark.extensions.IcebergSparkSessionExtensions spark.sql.defaultCatalog tabular spark.sql.catalog.tabular org.apache.iceberg.spark.SparkCatalog spark.sql.catalog.tabular.catalog-impl org.apache.iceberg.rest.RESTCatalog spark.sql.catalog.tabular.uri https://api.tabular.io/ws spark.sql.catalog.tabular.credential <YOUR TABULAR CRED> spark.sql.catalog.tabular.warehouse <YOUR WAREHOUSE NAME>
Finally, restart the cluster.
Step 4: The Code
Create a new NOTEBOOK and see all three tools start working in tandem by running few DDL and DML queries.
show databases;
create able pingpongdb.myicebergtable (id bigint, data string) using iceberg;
insert into pingpongdb.myicebergtable values (1, 'test');
select * from pingpongdb.myicebergtable;

Finally, let’s go back to Tabular console and see if the changes are getting reflected or not?

And we can see the newly created table “myicebergtable” inside “pingpongdb” database.
Conclusion
As was shown, getting started with Apache Iceberg with Tabular in Databricks is pretty simple. No matter which vendor makes the engine you want to utilize, using the trio of Apache Iceberg and Tabular in Databricks enables you to use the optimum engine for the workload.