Building Serverless Data Pipelines with AWS Lambda, PyIceberg, and Tabular


In this blog, we will cover the benefits of using PyIceberg and Tabular from AWS Lambda and how easy it is to set up, integrate, and build cost effective data pipelines. The focus of this blog would be on how to setup the whole infrastructure with Tabular Catalog, but it would work with other supported catalogs like Glue Catalog or Hive.
Advantages of PyIceberg + Tabular with AWS Lambda
Cost-optimized deployments: You only pay for the compute time you use with AWS Lambda, which automatically scales your application in response to the volume of requests. You can save money by using the AWS Lambda with PyIceberg to avoid overprovisioning massive clusters for minor use cases. You don’t always need expensive Spark clusters!
Highly scalable: With AWS Lambda, you can run code without setting up or managing servers and create apps that are simple to scale as requests increase. You may now easily build and expand data processing applications thanks PyIceberg!
Enhanced connectivity: By incorporating AWS Lambda, Python, Iceberg, and Tabular together, this technology stack will make a path for additional packages to benefit from this requirement, encouraging a bigger ecosystem of compatible software and tools.
How to setup?
There are two ways to run a Python script as a lambda in AWS if it makes use of modules that are not part of the Python Standard Library. The first step would be to build an AWS Lambda Layer that connects to the Lambda and contains all the packages. The second step would be to zip the lambda function and the modules together to make a package that can be uploaded and executed. The second choice will be covered in this post.
Installation of the dependencies
Just follow the below shell commands to get the required dependencies installed inside a working directory.
mkdir playground
cd playground
python3.9 -m venv venv
source venv/bin/activate
pip install pyiceberg
pip install pyarrow Code the data pipeline
We will limit our discussion in this blog post to the code necessary to connect PyIceberg to the Tabular catalog in order to keep things clear and straightforward.
touch lambda_function.py
vim lambda_function.pyJust to keep configuration simple we will use default filename and function name of AWS Lambda: lamba_fuction.py and lambda_handler
$ cat lambda_function.py
from pyiceberg.catalog import load_catalog
def lambda_handler(event, context):
catalog = load_catalog(
'default',
uri='https://api.tabular.io/ws/',
warehouse='<WAREHOUSE NAME>',
credential='<CRED SECRETS OF TABULAR>'
)
namespaces = catalog.list_namespaces()
return namespacesPackage and upload the bundle
Follow these steps to create a runnable bundle with dependencies.
cd venv/lib/python3.9/site-packages
zip -r9 ${OLDPWD}/function.zip .
cd $OLDPWD
zip -g function.zip lambda_function.py We now have a package that can be uploaded as an AWS Lambda function.
$ aws s3 cp function.zip s3://<YOUR BUCKET>Create and Configure AWS Lambda function
These are the standard steps required to set up a Lambda function on AWS.
Create Function

Upload jar from S3
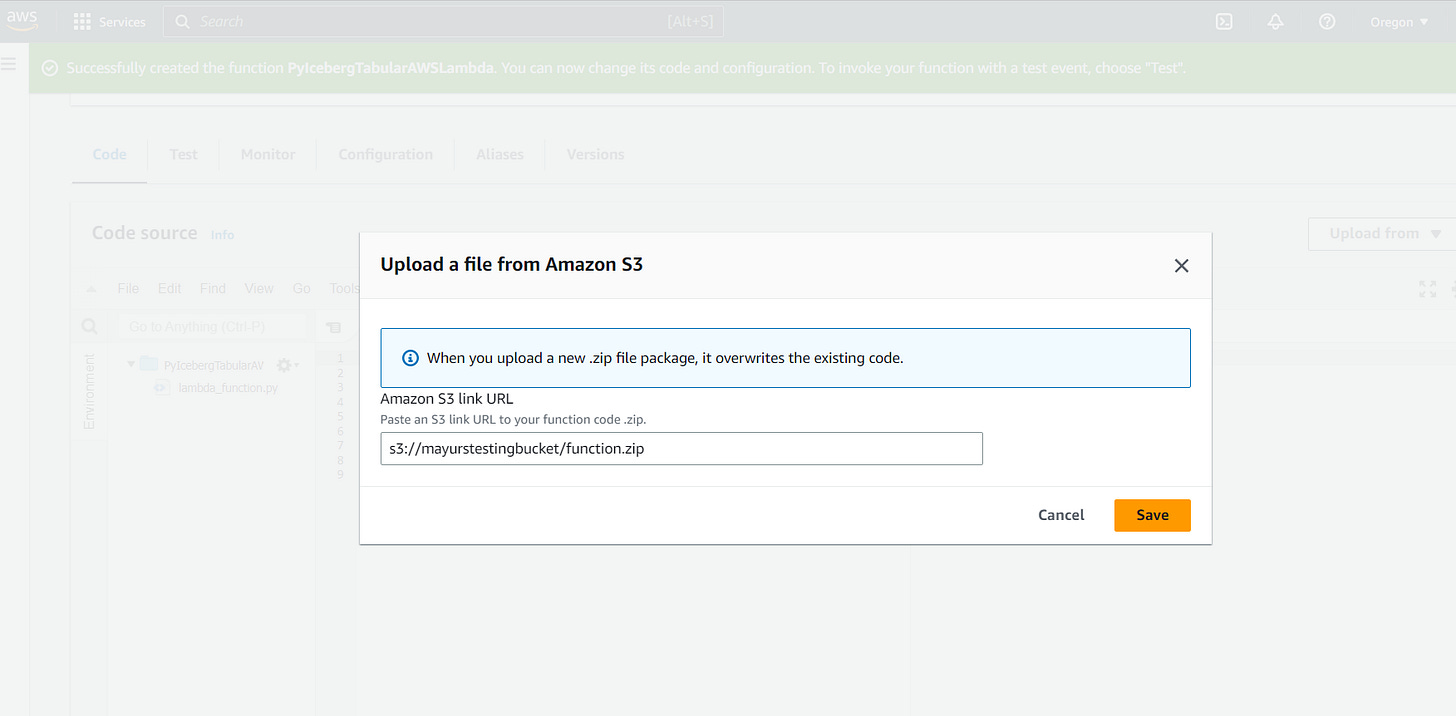


Now, our code is deployed as a function and ready for testing.
Test our code
Configure a dummy test event

Execute the function

Code is executed successfully, and we can see the list of Tabular namespaces in the output.

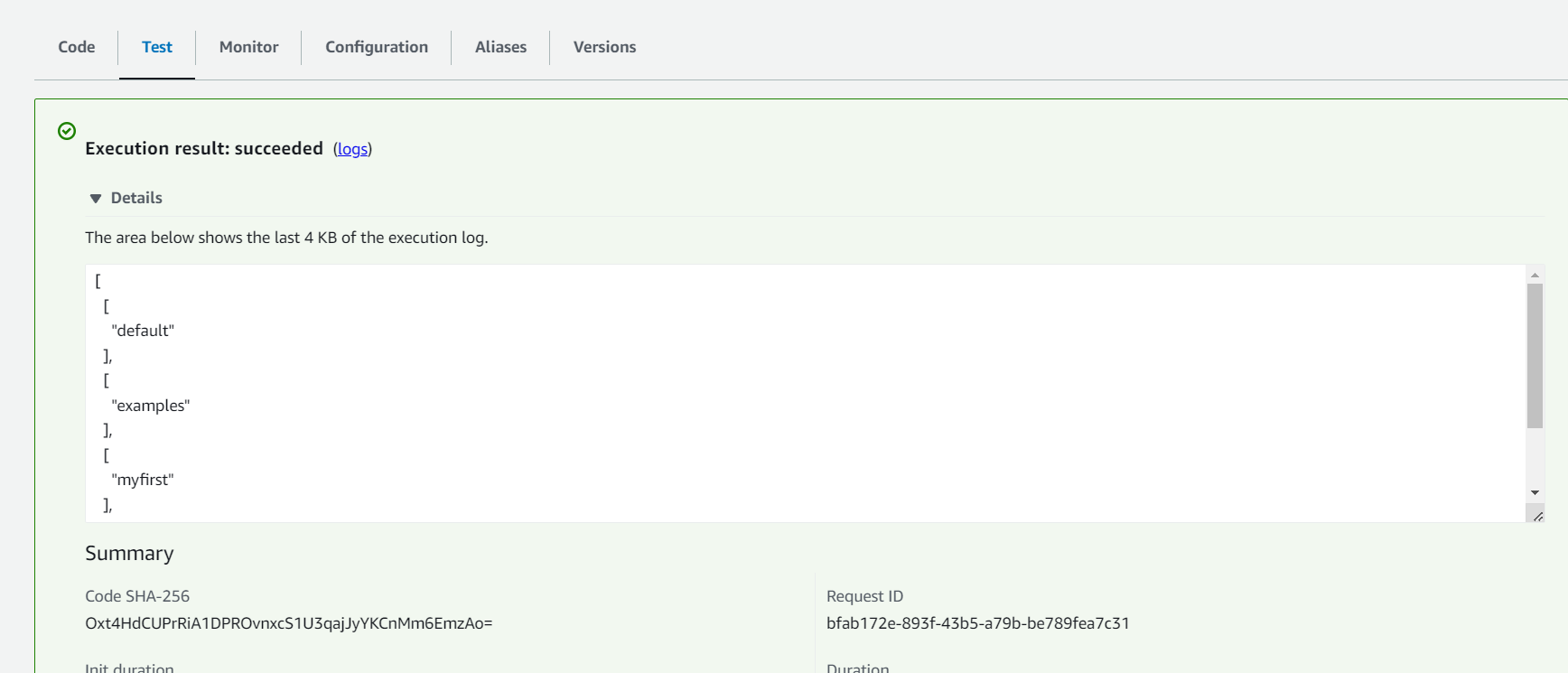
Conclusion
In conclusion, the combination of AWS Lambda, PyIceberg, and Tabular offers a robust and scalable solution for data processing and analytics tasks. By using these tools together, you can easily manage your data pipelines and improve your data analytics performance. With serverless computing, simplified data management, and SQL-like operations on tabular data, these tools provide an efficient and cost-effective way to handle complex data tasks.
In a future blog, we will cover how to connect other catalogs, like Hive or Glue, with AWS Lambda.
.