Auto Optimizing Apache Iceberg tables with Tabular: Best practices from a DBA standpoint – Part 1


Welcome to the first part of our blog series on auto-optimizing Apache Iceberg tables with Tabular from a DBA standpoint. In this series, we will explore the importance of optimizing Apache Iceberg tables for high performance and reliability, and how DBAs achieve this today (manually). We will cover best practices, common performance issues, and case studies of organizations that have successfully implemented optimization of their Apache Iceberg tables and how easy it is to automate the same with Tabular.
DBA’s Challenge: Eventually, query performance starts to deteriorate.
I just ran into a common problem with a number of my customers. They built some data warehouse workloads on top of Apache Iceberg, and everything went perfectly at first. But after a few days, the DBA started getting a large number of JIRA tickets pointing to a decline in query performance on a few tables. In the next section, we will discuss a scalable performance tuning technique that we applied across multiple customers.
DBA’s curious question: Why for a few tables only?
DBAs may wonder why only a few Apache Iceberg tables are experiencing performance issues, while others are running smoothly. It's a valid question, as understanding the RCA of the issue is the first step towards finding a solution. In the next section, we will cover an automated process we developed to discover the underlying issue.
Understanding metadata!
Metadata files are at the core of all of Iceberg's advanced features. To make these files more accessible to users, Iceberg provides metadata tables, which can be easily queried using SQL. Here are Apache Iceberg’s metadata tables:

Analyze the “snapshots” table.
Let’s find out the structure of the snapshots table:
%sql
describe table <DB>.<TABLE>.snapshots;
Going deep into the “summary” column
Take a look at what’s inside the summary map:
%sql
select * from <DATABASE>.<TABLE>.snapshots order by committed_at desc ;
Extract the relevant information.
Fetch the required column from the map for further use:
df = spark.sql("select summary from <DATABASE>.<TABLE>.snapshots order by committed_at desc limit 1")df.select('summary.total-files-size', 'summary.total-data-files').show()
Scatter plot in two-dimensional space
A visual representation of the data points would help us grasp the situation better. The produced scatter plot can be seen below, with “total-files-size” on the X axis and “total-data-files” on the Y axis. We lowered the sample size of tables to make things simple and easy to comprehend.

Quick inference from the plot
Area 1: Small File Problem (Area of Concern)
Area 2: Large File Problem (Area of Concern)
Area 3: Well-balanced tables
How do I quickly fix the issue?
Now that we've identified the root cause of the issue, let's fix it. To compress data files in Spark SQL, Apache Iceberg provides a stored method. This will combine small files into larger files, reducing metadata overhead and file open costs during runtime.
Run “rewriteDataFiles” stored procedure at regular intervals
CALL tabular.system.rewrite_data_files(
table => '<DB>.<TABLE>',
options => map('target-file-size-bytes','<SIZE>')
)How do I fix it permanently?
Configure the table properties in DDLs.
Make sure to configure the file size right!
ALTER TABLE <DB>.<TABLE> SET TBLPROPERTIES ( 'write.target-file-size-bytes'='<ACCORDING_TO_USE_CASE>' )Remove the old settings from DML/Workloads.
After digging into the customer's codebase, a few settings that were required in prior versions of Spark but do not align with Spark 3.x (AQE) and table formats such as Apache Iceberg were discovered.
Make sure to remove old settings from codebase
dataframe.coalesce(X)dataframe.repartiton(Y)SET spark.sql.shuffle.partitions = 200/<some static value>
‘Fully Managed’ Maintenance with Tabular
So far, we've discussed the problem statement and how DBAs are currently manually resolving the imbalanced file size issue. What if it could be totally automated and handled for you? When it comes to automating data warehouse maintenance tasks, Tabular can be extremely handy.
In this section, I will demonstrate how, with "zero" action, we can prevent such maintenance issues from occurring in the first place.
Step 1: Let’s create some small files and load them into the Apache Iceberg table.
Using an open source tool, dbldatagen from Databricks, to simulate the load from different workloads
Simulating default value of Spark shuffle partitions - 200

Step 2: Take a look at the state of the data in the Tabular console.
* The first snapshot of the table created with the initial load

* Drill down into the summary of the table to verify the “added-data-files” property.
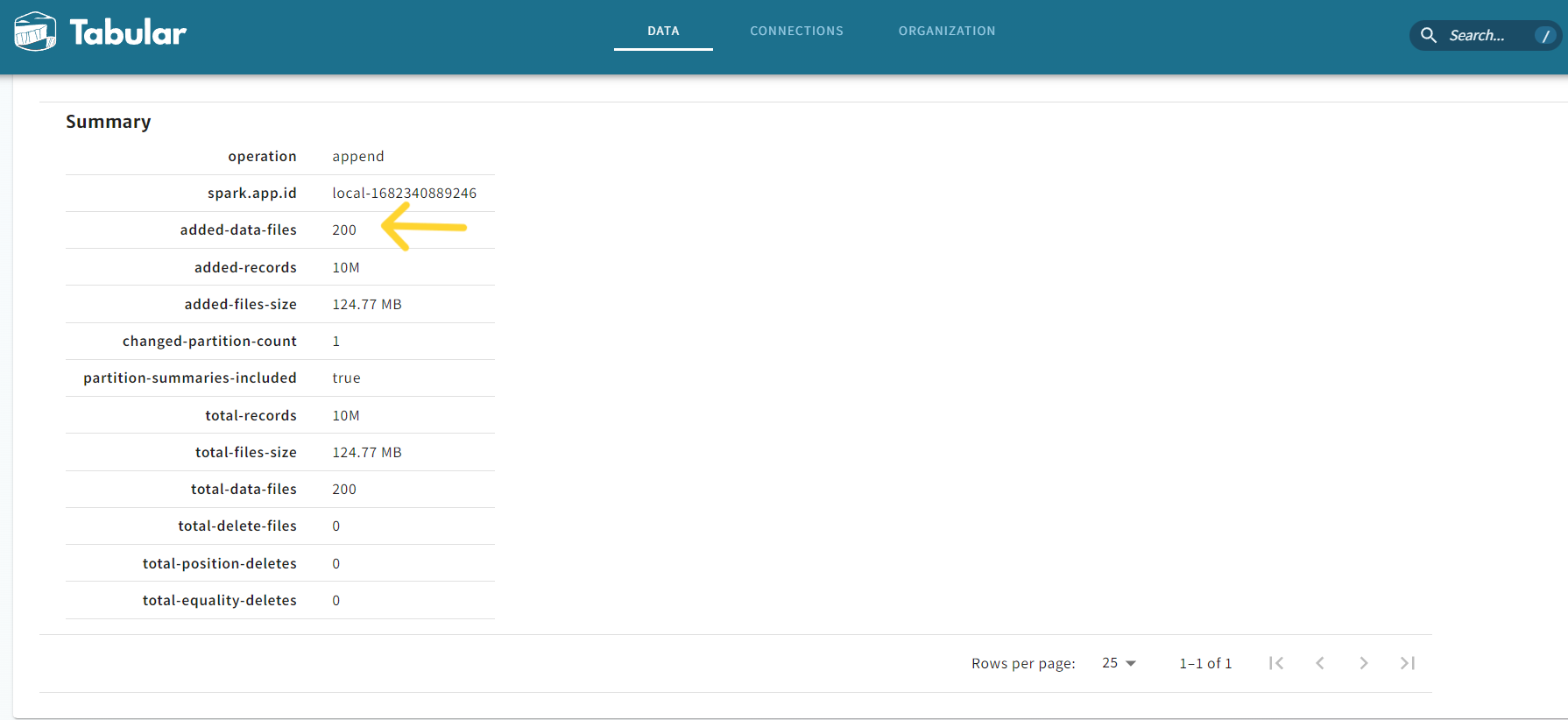
* Verify the number of files created on S3 (200).

Step 3: Do nothing and wait for a few minutes.
Table maintainence is fully managed by Tabular. No Op required!
Step 4: Again, take a look at the state of the data in the Tabular console.
After a few minutes, Tabular will take over and automate the "rewrite-data-files" procedure, as well as self-optimize the table with a new snapshot.

Verify the activities performed behind the scenes in the Activity tab. As part of the operation, 200 data files get deleted and compacted into 1 data file (depending on the size of the data and configuration).

Let’s check the state of the S3 bucket; a new file has been created (total 201).

Conclusion
In conclusion, optimizing Apache Iceberg tables is a critical aspect of ensuring high performance and reliability in your data infrastructure. As we've seen in this blog series, DBAs have traditionally achieved this through manual processes and best practices, but there is an opportunity to make this task much easier and more efficient by leveraging automation tools like Tabular. By automating the optimization of Apache Iceberg tables, organizations can ensure that their data infrastructure is running at peak performance with minimal human intervention.
This blog post is the first part of a series about optimization from the DBA’s perspective. I will cover the other use cases in future blog posts.